Raspberry Pi und S7 – geht das?
Im Zuge der Vorgaben, die wir beim ersten Team-Meeting vor den Sommerferien erhalten haben, stand für uns natürlich ein Problem im Raum: Wie bekommen wir das auf die Reihe? In einer Welt voller Schnittstellen und der zugehörigen Portion Chaos könnte das eine durchaus interessante Herausforderung werden.
Für uns war jedoch relativ schnell klar, dass wir uns nach Möglichkeit auf die Produkte von Siemens festlegen (und das nicht, weil ich dort arbeite und Werbung dafür gemacht habe). Uns wurde seitens der Schule ein anderer Hersteller angeboten, allerdings wissen alle PZler aus ihrer Erfahrung heraus, dass dieser Hersteller mit Frust, Verzweiflung und [beliebige negative Emotion hier einfügen] verbunden ist. Ungeachtet dessen, welcher Hersteller nun Anwendung findet, bleibt die Auseinandersetzung mit der Thematik der Schnittstellen ein großer Punkt auf der Agenda – gerade bei einem Raspberry Pi ist das auch ein sehr interessantes Thema. Halten wir aber zunächst am Hersteller Siemens mit der S7 fest. Aus dem aktuellen Portfolio ist ersichtlich, dass die S7-300er Serie nicht mehr zur Verfügung steht, da diese nicht mehr verkauft wird. Die S7-400er Serie ist preislich auf einem Niveau, das nicht unbedingt erschwinglich ist und auch sehr wahrscheinlich nicht gesponsort wird. Was wir allerdings leihweise erhalten haben, ist eine S7-1211C DC/DC/RLY mit der die Verbindung und Vernetzung zwischen Raspberry Pi und S7 mal getestet werden kann.
Nun bleibt noch die Frage offen, wie eine Verbindung zu Stande kommt, da die S7 ja eigentlich von Hause aus nur über PROFINET kommuniziert. Und genau da kommt die Python-Bibliothek „snap7“ ins Spiel. Diese Bibliothek wandelt die Datenprotokolle für eine S7-Kommunikation um, ein eigenes Protokoll, das zur Kommunikation zwischen S7-CPs verwendet wird. Auf Layer 1 und 2 im OSI-Modell befinden wir uns zwar weiterhin in der Welt von Ethernet, allerdings kommt in Layer 5 das S7-Protokoll zum Einsatz.

Weitergehende Informationen zum Protokoll-Aufbau und der Funktion der Bibliothek sollen hier nun allerdings nicht Gegenstand des Beitrags sein. Weitere Informationen dazu sind in der offiziellen Dokumentation von Snap7 zu finden.
Nachdem die Bibliothek mit Hilfe von PIP installiert wurde, war nun noch die Frage, wie eine Verbindung aufgebaut werden kann. Hierzu liefert allerdings die Dokumentation von snap7 für Python ausreichend Lesestoff, sodass dies in relativ knappen Zügen zusammengefasst wie folgt funktioniert:
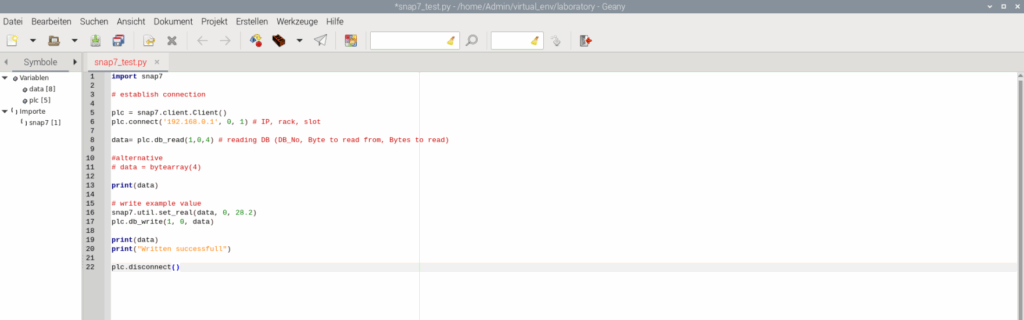
Man unterscheidet bei dieser Verbindung zwischen Client, Server und Partner (wird in unserem Fall nicht verwendet). In dem Fall dieser Konstellation ist die S7 der Server und der Raspberry Pi der Client. Folglich wird eine Verbindung auch mit dem Klassen-Befehl .client.Client() in Kombination mit .connect() aufgebaut.
plc= snap7.client.Client()
plc.connect('192.0.20.1', 0, 1)Dabei dient „plc“ lediglich der Instanziierung der Objekt-Klasse und mit .connect wird die Adressierung durch IP-Adresse, Racknummer und Einbauslot vorgenommen. Um nun Daten abzufragen benötigen wir auf der S7-Seite einen Datenbaustein, der allerdings nicht mit der Option „optimiert“ vorliegen darf (bei dieser Option geht es um die Speicherverwaltung innerhalb des Datenbausteins – in optimierter Variante wird der Speicher so verwendet, wie er effektiv für Daten benötigt wird, folglich Variabel… bei nicht optimierter Variante bleibt der Speicher je Datenpunkt fest bestehen, auch wenn diese den Speicherplatz nicht gänzlich benötigt).
Die nicht optimierte Variante wird benötigt, um den Speicherplatz explizit ansprechen zu können, da wir nun beginnen mit Zeigern zu arbeiten. Um also gewisse Daten abzufragen, benötigt man die Nummer des Datenbausteins (da diese der Adresse des Bausteins entspricht und auch innerhalb der S7 einmalig vergeben werden kann), das Startbyte von dem aus gelesen werden soll und die Anzahl der Bytes, die gelesen werden sollen – anschließend kann mit .db_read() die Abfrage erfolgen.
data = plc.db_read(1, 0, 4)Die erhaltenen Daten werden dann wiederum in einer Variablen gespeichert. Nachteil bei Python ist an der Stelle leider, dass es keine feste Variablendeklaration wie bei anderen objektorientierten Programmiersprachen gibt. Das hat zur Folge, dass eine Variable mit allen Datentypen automatisch gefüllt werden kann. Fehler sind damit leider etwas schwerer aufzuspüren, da es bei einer Verschiebung der Byteabfrage keine direkte Rückmeldung dazu gibt, außer einen Wert, der nicht mehr plausibel erscheint. Es ist also definitiv mit erhöhter Aufmerksamkeit zu arbeiten, wenn es um die Adressierung geht.
Auf eine ähnliche Weise können natürlich auch Werte in den Datenbaustein geschrieben werden. Hierfür wird nur .db_write() benötigt. Die Adressierung bezieht sich hier wieder auf die Nummer des Datenbausteins, das Startbyte, ab dem geschrieben werden soll, dann allerdings die Daten, die in den vom Datenbaustein erwarteten Datentyp konvertiert worden sind.
Und zu guter Letzt wird die Verbindung zwischen Raspberry Pi und S7 wieder getrennt, um den Traffic auf der Leitung etwas zu reduzieren – wobei wir an dieser Stelle seitens der S7 sowieso nicht in Echtzeit arbeiten, was also zusätzlich verschwendete Rechenleistung auf dem Raspberry Pi wäre. Und Wenn alles richtig funktioniert, kann ein Programm zur Kommunikation wie folgt aussehen: